
Documents
Vantage Ingestion Format
The documents (or records) you ingest or upload into your collections must conform to specific field and format requirements. This is what we call the Vantage Ingestion Format (VIF). You must use this schema and conventions for both JSONL format and Parquet format when uploading via the Console UI, an upload file, or the upload documents API. All field names are lower case, except where noted.
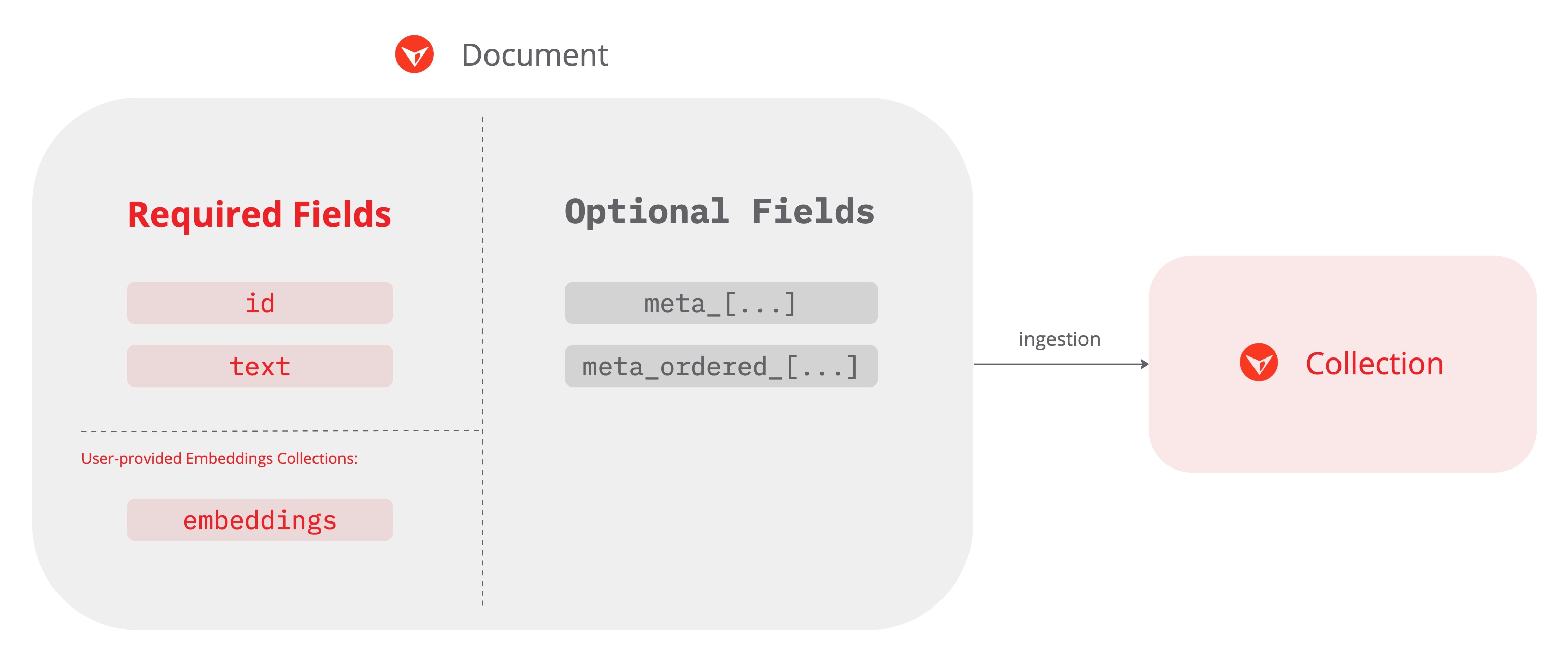
Required Fields
id
idThis represents your ID for this document. It will be handed back to you in search results.
- Length: 1 to 256 characters
{
"id": "http://mydomain.com/products/1234567"
}
{
"id": "product-id-12345"
}
{
"id": "9938173"
}
text
textThis field is the text that will be embedded using your provided model. It should be a UTF-8 string, zero to 1GB in size.
embeddings
embeddingsThis is an array of 32-bit floating point numbers (4 bytes each). The array length should match the Dimension Size of the collection you're putting data into. For instance, if you're using OpenAI's text-embedding-ada-002 model which has a dimension size of 1536, your embeddings array length should be 1536.
Also, the embeddings vector should be a proper unit vector in order to perform the collection operations successfully.
Vantage Managed Embeddings (VME) or User Provided Embeddings (UPE)
During ingestion you must include either
textorembeddingsdepending on if Vantage is managing embeddings for you or you are providing them.
{
"id" : "123",
"text" : "The quick brown fox jumps over the lazy dog"
}
{
"id" : "document-100",
"embeddings" : [-0.010061902925372124, -0.017514921724796295, .... ]
}
File with both
textandembeddingsIf your file includes both, the
embeddingsfield takes precedence and we will use it instead of re-embedding thetext. That means, even if you are using Vantage Managed Embeddings and normally thetextwould be processed, theembeddingswould be used instead. This may be useful if you have already created embeddings for the data your are ingesting to the Vantage Platform.
Optional Fields
operation
operationThis field specifies the action to be performed on the document. The available options are:
delete: Deletes document.update: Adds a new document ifidof the document does not already exist or updates an existing document.
By default, the update option is used.
deleteoperation requirementsIf the
deleteoperation is set, the only other required field isid.
During delete, only one operation (delete) should be applied across all documents in the same ingestion file.
meta_ fields
meta_ fieldsOther fields, prefixed with meta_, can be provided to support querying and filtering. A document can have any number of these fields.
meta_<fieldname> is a field that should be indexed for search query filtering. The <fieldname> is case-sensitive. meta_FieldName is different from meta_fieldname.
The <fieldname> part of the field has specific naming restrictions:
- Characters: May contain only [a-zA-Z0-9-_] characters
- Minimum length: 3 characters
- Maximum length: 255 characters
The values of these fields can only be these types:
- Scalar Single Values:
meta_<fieldname> : int, string, float - Array or List Values:
meta_<fieldname> : [int], [string], [float]
The
meta_prefix is only used in the ingestion format. During querying, themeta_prefix is dropped.
meta_ordered_ fields
meta_ordered_ fieldsIn addition to meta_ fields, there are meta_ordered_ fields, which adhere to the same guidelines as meta_ fields but serve an additional purpose: sorting search results.
meta_ordered_<fieldname> is a field that should be indexed for sorting search query results. The <fieldname> is case-sensitive. meta_ordered_FieldName is different from meta_ordered_fieldname.
The <fieldname> part of the field has specific naming restrictions:
- Characters: May contain only [a-zA-Z0-9-_] characters
These fields are specifically designed for organizing results based on their values. For detailed instructions on utilizing meta_ordered_ fields, please refer to Search Options page.
The
meta_ordered_prefix is only used in the ingestion format. During querying, themeta_ordered_prefix is dropped.
meta_facet_ fields
meta_facet_ fieldsIn addition to the meta_ and meta_ordered_ fields, there are also meta_facet_ fields, which follow the same guidelines as the meta_ and meta_ordered_ fields but are specifically used to enable filtering on object facets.
meta_facet_<fieldname> is a field that should be indexed for filtering search query results or used for counting available objects with the current facet. The <fieldname> is case-sensitive. meta_facet_FieldName is different from meta_facet_fieldname.
The <fieldname> part of the field has specific naming restrictions:
- Characters: May contain only [a-zA-Z0-9-_] characters
These fields are specifically designed for organizing results based on their values. For detailed instructions on utilizing meta_facet_ fields, please refer to Search Options page.
The
meta_facet_prefix is only used in the ingestion format. During querying, themeta_facet_prefix is dropped.
variants
variantsAn additional field which can be uploaded for each document, representing a specific variant of that document or product based on a unique attribute combination. If provided, it allows users to manage variants of the same product without cluttering search results with duplicates. Users can also filter results based on the variant attribute values using variant_filter during a search.
Variants are specified using variants field, which is a list of structs describing each variant. Each variant has mandatory id field, with all other fields being arbitrary.
For example:
[{'id': '1', 'color': 'red', 'size': 'M'}, {'id': '2', 'color': 'red', 'size': 'XS'}]
Updated about 2 months ago